-
Humanitaarteaduste ja kunstide valdkondHumanitaarteaduste ja kunstide valdkonna dekanaatJakobi 2, r 116-121 51005 Tartu linn, Tartu linn, Tartumaa EST0Ajaloo ja arheoloogia instituutJakobi 2 51005 Tartu linn, Tartu linn, Tartumaa EST0Eesti ja üldkeeleteaduse instituutJakobi 2, IV korrus 51005 Tartu linn, Tartu linn, Tartumaa EST0Filosoofia ja semiootika instituutJakobi 2, III korrus, ruumid 302-337 51005 Tartu linn, Tartu linn, Tartumaa EST0Kultuuriteaduste instituutÜlikooli 16 51003 Tartu linn, Tartu linn, Tartumaa EST0Maailma keelte ja kultuuride instituutLossi 3 51003 Tartu linn, Tartu linn, Tartumaa EST0UsuteaduskondÜlikooli 18 50090 Tartu linn, Tartu linn, Tartumaa EST0Viljandi kultuuriakadeemiaPosti 1 71004 Viljandi linn, Viljandimaa EST0Humanitaarteaduste ja kunstide valdkonna emeriitprofessorid0Humanitaarteaduste ja kunstide valdkonna emeriitdotsendid0Sotsiaalteaduste valdkondSotsiaalteaduste valdkonna dekanaatLossi 36 51003 Tartu linn, Tartu linn, Tartumaa EST0Haridusteaduste instituutJakobi 5 51005 Tartu linn, Tartu linn, Tartumaa EST0Johan Skytte poliitikauuringute instituutLossi 36, ruum 301 51003 Tartu linn, Tartu linn, Tartumaa EST0MajandusteaduskondNarva mnt 18 51009 Tartu linn, Tartu linn, Tartumaa EST0Psühholoogia instituutNäituse 2 50409 Tartu linn, Tartu linn, Tartumaa EST0ÕigusteaduskondNäituse 20 - 324 50409 Tartu linn, Tartu linn, Tartumaa EST0Ühiskonnateaduste instituutLossi 36 51003 Tartu linn, Tartu linn, Tartumaa EST0Narva kolledžRaekoja plats 2 20307 Narva linn, Ida-Virumaa EST0Pärnu kolledžRingi 35 80012 Pärnu linn, Pärnu linn, Pärnumaa EST0Sotsiaalteaduste valdkonna emeriitprofessorid0Sotsiaalteaduste valdkonna emeriitdotsendid0Meditsiiniteaduste valdkondMeditsiiniteaduste valdkonna dekanaatRavila 19 50411 Tartu linn, Tartu linn, Tartumaa ESTBio- ja siirdemeditsiini instituutBiomeedikum, Ravila 19 50411 Tartu linn, Tartu linn, Tartumaa ESTFarmaatsia instituutNooruse 1 50411 Tartu linn, Tartu linn, Tartumaa ESTHambaarstiteaduse instituutL. Puusepa 1a 50406 Tartu linn, Tartu linn, Tartumaa ESTKliinilise meditsiini instituutL. Puusepa 8 50406 Tartu linn, Tartu linn, Tartumaa ESTPeremeditsiini ja rahvatervishoiu instituutRavila 19 50411 Tartu linn, Tartu linn, Tartumaa ESTSporditeaduste ja füsioteraapia instituutUjula 4 51008 Tartu linn, Tartu linn, Tartumaa ESTMeditsiiniteaduste valdkonna emeriitprofessorid0Meditsiiniteaduste valdkonna emeriitdotsendid0Loodus- ja täppisteaduste valdkondLoodus- ja täppisteaduste valdkonna dekanaatVanemuise 46 - 208 51003 Tartu linn, Tartu linn, Tartumaa ESTArvutiteaduse instituutNarva mnt 18 51009 Tartu linn, Tartu linn, Tartumaa ESTGenoomika instituutRiia 23b/2 51010 Tartu linn, Tartu linn, Tartumaa ESTEesti mereinstituutMäealuse 14 12618 Tallinn, Harjumaa EST0Füüsika instituutKeemia instituutRavila 14a 50411 Tartu linn, Tartu linn, Tartumaa EST0Matemaatika ja statistika instituutNarva mnt 18 51009 Tartu linn, Tartu linn, Tartumaa EST0Molekulaar- ja rakubioloogia instituutRiia 23, 23b - 134 51010 Tartu linn, Tartu linn, Tartumaa ESTTartu observatooriumObservatooriumi 1 61602 Tõravere alevik, Nõo vald, Tartumaa EST0TehnoloogiainstituutNooruse 1 50411 Tartu linn, Tartu linn, Tartumaa ESTÖkoloogia ja maateaduste instituutJ. Liivi tn 2 50409 Tartu linn, Tartu linn, Tartumaa ESTLoodus- ja täppisteaduste valdkonna emeriitprofessorid0Loodus- ja täppisteaduste valdkonna emeriitdotsendid0Bioinseneeria instituutNooruse 1 50411 Tartu linn, Tartu linn, Tartumaa ESTAkadeemilise sekretäri tegevusvaldkondPersonaliosakondUppsala 6, Lossi 36 51003 Tartu linn, Tartu linn, Tartumaa EST0Finantsjuhi tegevusvaldkondRahandusosakondJakobi 4 51005 Tartu linn, Tartu linn, Tartumaa EST0Kantsleri tegevusvaldkondInfotehnoloogia osakondUppsala 10 51003 Tartu linn, Tartu linn, Tartumaa EST0KantseleiÜlikooli 17 (III korrus) 51005 Tartu linn, Tartu linn, Tartumaa EST0Kinnisvaraosakond0Turundus- ja kommunikatsiooniosakondÜlikooli 18, ruumid 102, 104, 209, 210 50090 Tartu linn, Tartu linn, Tartumaa EST0Arendusprorektori tegevusvaldkondEttevõtlus- ja innovatsioonikeskusNarva mnt 18 51009 Tartu linn, Tartu linn, Tartumaa EST0Loodusmuuseum ja botaanikaaedVanemuise 46 51003 Tartu linn, Tartu linn, Tartumaa EST0Rahvusvahelise koostöö ja protokolli osakond0MuuseumLossi 25 51003 Tartu linn, Tartu linn, Tartumaa EST0Rektori tegevusvaldkondRektoraadi bürooÜlikooli 18 50090 Tartu linn, Tartu linn, Tartumaa ESTSiseauditi bürooÕppeprorektori tegevusvaldkondÕppeosakondTeaduskoolUppsala 10 51003 Tartu linn, Tartu linn, Tartumaa EST0Üliõpilaskonna bürooÜlikooli 18b 51005 Tartu linn, Tartu linn, Tartumaa EST0Õppimis- ja õpetamiskeskusLossi 36-401 51003 Tartu linn, Tartu linn, Tartumaa ESTTeadusprorektori tegevusvaldkondTartu Ülikooli raamatukoguW. Struve 1 50091 Tartu linn, Tartu linn, Tartumaa EST0GrandikeskusRaekoja plats 9, III korrus 51004 Tartu linn, Tartu linn, Tartumaa EST
mikroobsete patogeenide DNA tuvastamine inimese verest
haruldaste ja väheuuritud variatsioonide leidmine
toidu koostise ja päritolu määramine toidus leiduva DNA abil
genoomijärjestuste usaldusväärne ja kiire analüüs
Bioinformaatika uurimisgrupp
Meie üldine eesmärk on arendada arvutusalgoritme genoomijärjestuste usaldusväärseks ja kiireks analüüsiks. Mõned näited:
* antimikroobse resistentsuse ennustamine ja plasmiidide tuvastamine bakterikoloonia DNA järjestusest [1,2];
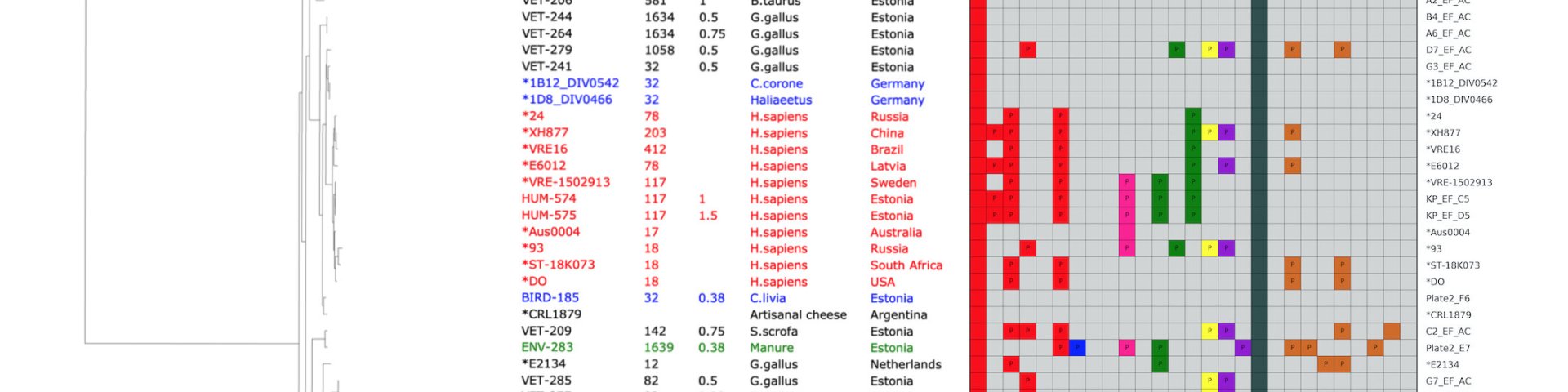
* mikroobsete patogeenide DNA tuvastamine inimese verest (rakuvaba DNA fraktsioonist), reoveest või muudest allikatest;
* haruldaste ja väheuuritud variatsioonide leidmine (Alu-elemendid, endogeensed retroviirused, rRNA geenide koopia arv, jms.) inimeste personaalsetest genoomi järjestustest [3,4];
* toidu koostise ja päritolu määramine toidus leiduva DNA abil [5].
Kaugemas plaanis soovime luua täieliku komplekti tarkvara ja ennustusmudeleid, mis võimaldaksid täpsemalt jälgida meid ümbritsevat keskkonda sh. meid ümbritsevaid patogeene, inimese mikrobioomi ja meie toitu.
- Oselin, K., Kaplinski, L., Jääger, A., Valter, A., Puurand, T. jt. (2023). Comparative Genomic Analysis to Distinguish Triple Metachronous Lung Carcinoma from Metastatic Recurrence: Brief Report on First Case Treated with Three Consecutive VATS Lobectomies. Annals of Medical and Clinical Oncology 5 (145)
- Pajuste, F.D., Remm, M. (2023). GeneToCN: an alignment-free method for gene copy number estimation directly from next-generation sequencing reads. Scientific Reports, 13 (17765)
- Kaplinski, L., Möls, M., Puurand, T., Remm, M. (2023). DOCEST—fast and accurate estimator of human NGS sequencing depth and error rate. Bioinformatics Advances, 3 (1)
- Kaplinski, L., Möls, M., Puurand, T., Pajuste, F.D., Remm, M. (2021). KATK: Fast genotyping of rare variants directly from unmapped sequencing reads. Human Mutation, 42(6):777-786
- Raime, K., Krjutškov, K. Remm, M. (2020). Method for the Identification of Plant DNA in Food Using Alignment-Free Analysis of Sequencing Reads: A Case Study on Lupin. Front. Plant Sci., 11:646
- Puurand, T., Kukuškina, V., Pajuste, F.D., Remm, M. (2019). AluMine: alignment-free method for the discovery of polymorphic Alu element insertions. Mobile DNA, 10:31
- Roosaare, M., Puustusmaa, M., Möls, M., Vaher, M., Remm, M. (2018). PlasmidSeeker: identification of known plasmids from bacterial whole genome sequencing reads. PeerJ, 6: e4588
- Aun, E., Brauer, A., Kisand, V., Tenson, T., Remm, M. (2018). A k-mer-based method for the identification of phenotype-associated genomic biomarkers and predicting phenotypes of sequenced bacteria. PLoS Computational Biology, 14(10):e1006434
Maa Elu - Postimees, 09.01.2025. Mullu nii Eestis kui maailmas laineid löönud mee DNA-testi loonud meeskond töötab nüüd välja metoodikat, et tuvastada meest mesilasi ohustavaid RNA-viiruseid, mis valmistavad peavalu ja majanduslikku kahju mesinikele üle maailma. Artiklis tutvustab projekti lähemalt Celvia CC AS toiduvaldkonna juht Kairi Raime.
25.09.2024 loodus- ja reaalainete õpetajate teaduspäeva programmis osalemine (bioloogilised andmebaasid)
Tartu Ülikooli teaduskooli kaudu läbi viidav bioinformaatika teemaline kursus gümnaasiumiõpilastele (järjepidevalt alates õppeaastast 2021/2022)
Toidu koostise, päritolu ja ohutuse jälgimine toidus oleva DNA järjestamise abil
Ettevõtetega koostöös otsitakse võimalusi veremürgituse kiiremaks diagnoosimiseks